


Edit check programming and testing is time consuming and labor intensive. As such, it is efficient to minimize the time spent on programming by getting it right the first time. Historically, data management have measured edit check success as the percentage of edit checks that pass User Acceptance Testing (UAT). However, that may not be the best measure. What if an alternative metric leveraging Lean Six Sigma Methodology was used? The Rolled Throughput Yield (RTY) is a metric often employed in manufacturing operations to detect the probability that a process with more than one step will produce a defect free unit. If we track this metric for the edit check process, we can better gauge the probability of success of the edit check program.
Consider the following:
John, the Lead Data Manager on a study, develops the edit check specifications defining 100 edit checks requiring programming. Jane, the Database Programmer, receives the edit checks and programs them according to the specifications. When programming is complete, the checks are submitted for UAT and moved to production once successful testing is complete.
In this example, assume that 5 edit checks fail the UAT process and need to be reprogrammed. Therefore, our UAT Success Rate is 95%. Nice job, team!
95 Successful: 95/100 = .95 UAT Success Rate
What the UAT Success Rate does not measure, however, are the efficiencies and inefficiencies leading up to the final UAT test. Before being lulled into satisfaction and basking in the glory of their success, let’s provide Jane and John with another metric by which they can measure success, the RTY:
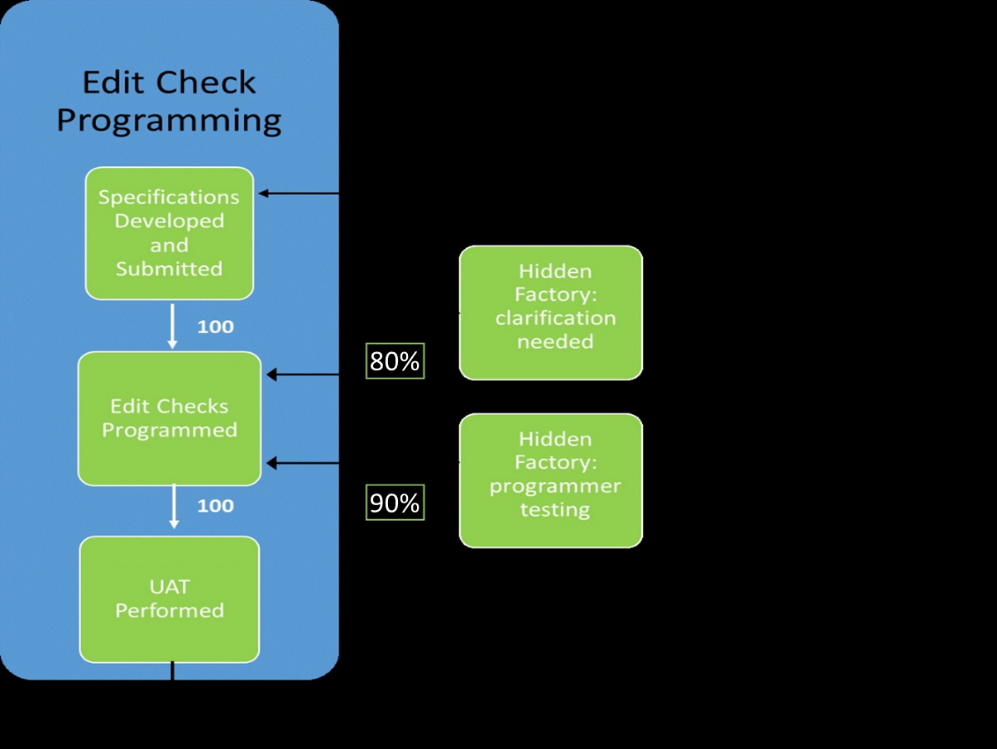
Using that same example, what we did not see earlier was that after receiving the specification for the 100 edit checks, Jane realized that she needed to seek clarification from John on 20 of the checks. Perhaps the language was unclear, the logic was inconsistent with the text, or some other reason required additional back and forth communication. Regardless of the reasons, this extra step in the process took time to correct 20% of the specifications (20 of the original 100). As a throwback reference to the method of identifying defects in manufacturing plants, extra steps such as this can be referred to as “Hidden Factories.” In this hidden factory within the overall process of edit check programming, our In-Process Yield (IPY) was 80%. That is, of the 100 edit check specifications, 80 were ready for programming without any clarification.
Once the 20 specifications were corrected, Jane continued programming. Recognizing that there may still be errors with either the specifications or her own programming, Jane did some informal testing before ever submitting them to UAT. Like most programmers, she typically does her own testing first and this is another hidden factory in the process. Through this programmer testing step, Jane found that she needed to reprogram 10 of the 100 checks. The IPY for this step was 90%.
Finally, Jane submitted her programs for the final UAT mentioned earlier in the article, which resulted in 95 successful checks and 5 failures, returning us to our original metric of 95% Success. The RTY, on the other hand, is calculated as the product of the success rates at each step of the process (IPYs). In this case, the RTY is 80% * 90% = 72%. Clearly this metric paints a different picture than the 95% UAT success. The diagram below depicts the high-level process of edit check programming with the added hidden factories of specification clarification and programmer-level testing.
In summation, the RTY isn’t meant to deflate John’s and Jane’s egos, but instead to provide an opportunity to more closely evaluate each step in the process and measure overall success according the success at each step in the process. The RTY doesn’t suggest that the hidden factories are necessarily inefficient but allows us to seek opportunities to reduce the time needed for each step, improving the individual IPYs. By delving into the process at this level, we will be able to improve the overall effort needed and perhaps bring the database to activation sooner.

